Clustering
Segmentatie versus Clustering: de Verdieping
Segmentatie versus Clustering: de Verdieping. Ondertussen zijn er van onze hand al twee artikelen verschenen over Clustering. Het artikel van Persona naar cluster waarin wordt ingegaan op de praktische toepassing van clustering en het artikel Segmentatie versus Clustering; deel 1 ons artikel over de verschillen tussen segmentatie én clustering.
Heb je naar aanleiding hiervan behoefte aan meer diepgang? Lees dan vooral verder! In dit artikel duiken we namelijk dieper in de materie en worden verschillende clusteralgoritmes en clusterevaluatie toegelicht. Het is namelijk niet noodzakelijk om een data scientist te zijn om clusteralgoritmes te begrijpen.
Welke ingrediënten zijn nodig om gebruik te kunnen maken van deze variant van unsupervised machine learning? Er moet een dataset zijn waarin elke rij data bevat over een unieke klant, bezoeker of profiel. Dit kan om klantwaarde gaan, maar context- of gedragsvariabelen kunnen ook worden meegenomen. Het principe van unsupervised machine learning is dat algoritmes patronen leren uit ongelabelde data. In deze situatie betekent dit dat er van tevoren nog géén clusters zijn gemaakt en er nog geen personen aan clusters zijn toegewezen.
Clustertechnieken
Er zijn verschillende technieken om personen aan clusters toe te wijzen. Drie algoritmen zullen in dit artikel Segmentatie versus Clustering: de Verdieping, verder worden uitgediept.
Voor meer algemene informatie over clustering, lees het artikel Segmentatie versus Clustering.
”Goede clusters geven meer en beter inzicht in je bezoekers.
Zo kun je bestaande segmentatie versterken en échte persona’s vinden.”
 k-Means
k-Means
 k-Means
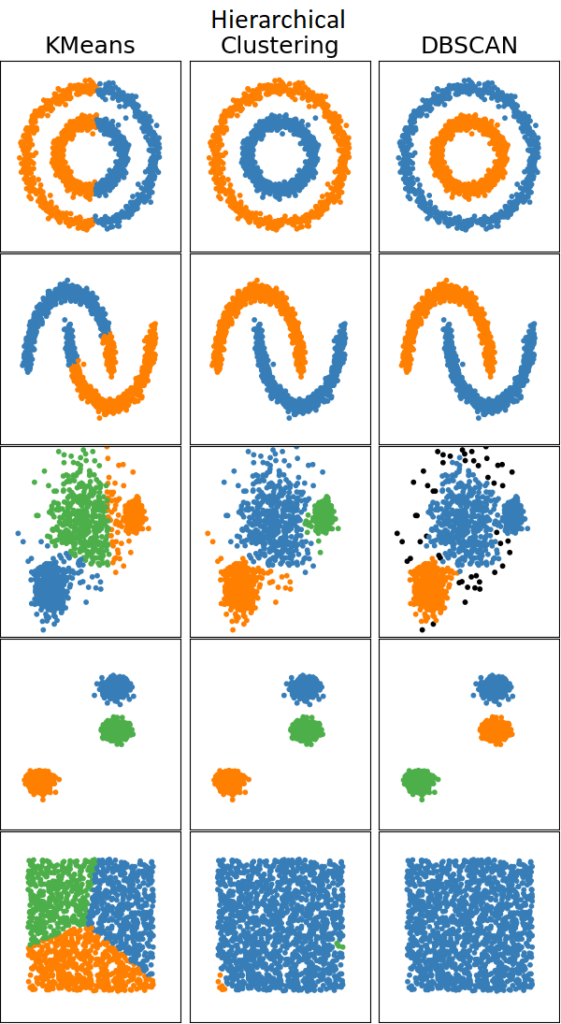
k-Meansk-means clustering is misschien wel de bekendste en meest gebruikte methode om te clusteren. In het geval van k-means wordt de beschikbare data in k clusters verdeeld. Het aantal van k wordt vooraf bepaald, dit kan bijvoorbeeld met de Elbow Method. In dit voorbeeld gaan we ervan uit dat 4 het optimale aantal clusters is.
Als we ons indenken dat alle zich in een multidimensionale ruimte bevinden waarbij elke variabele zo’n dimensie is, is er ook een meetbare afstand tussen alle datapunten. k-means plaatst vier punten in deze ruimte en wijst elk datapunt aan het meest dichtstbijzijnde van deze vier zwaartepunten toe. Zo zijn er vier clusters. De kans dat deze vier clusters ook de beste clusters op deze data zijn is zeer onwaarschijnlijk. Daarom worden de vier eerder geplaatste zwaartepunten verplaatst naar het middelpunt van de desbetreffende clusters en wordt elk datapunt opnieuw toegewezen aan het meest dichtstbijzijnde van deze vier punten. Door dit proces te herhalen totdat de middelpunten van de clusters niet meer verschuiven, wordt er naar de juiste clusterconfiguratie gezocht. Dit is de standaardmanier waarop een k-means algoritme clusters maakt, maar er zijn ook variaties.
Met een k-means algoritme is het namelijk mogelijk om een heel klein cluster te krijgen, of één heel groot cluster en drie kleinere. Met het oog op eventuele marketingcampagnes kan het wenselijk zijn om te sturen op clusters van gelijke grootte. Door dit aan het algoritme mee te geven, kunnen er meer gebalanceerde clusters gemaakt worden. Verder kan gekozen worden voor het aantal clusters dat eigen onderzoek of de marketingliteratuur aanbeveelt.

HCA
Een andere methode om te clusteren is een hiërarchische aanpak. De uitgangspositie van een Hiërarchische Cluster Analyse (HCA) is dat Een dataset met data van 1000 personen bevat dus 1000 clusters. Eerder is er al gesproken over de meetbare afstand tussen alle datapunten. In een volgende stap worden de twee punten met de kleinste onderlinge afstand samengevoegd tot een nieuw cluster, wat het totale aantal clusters verlaagt naar 999. Dit proces wordt herhaald tot er nog maar één cluster over is met daarin alle profielen. Op 1000 clusters is geen goede marketingstrategie te bedenken, maar op één cluster net zomin. Daarom wordt er retroactief gezocht naar het moment waar de afstand tussen de op dat moment aanwezige clusters voor het eerst groter is dan een vooraf gestelde drempelwaarde. Deze clusterconfiguratie geeft, volgens de HCA, de optimale clusters voor de betreffende dataset.

DBSCAN
Een derde veelgebruikte clustermethode is het Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algoritme. Deze methode richt zich op de manier waarop datapunten zich tot elkaar verhouden: gebieden van hoge en lage dichtheid. Wanneer er op deze manier naar de data gekeken wordt, is elk gebied met een hoge dichtheid een apart cluster. In tegenstelling tot een k-means algoritme, waar elk cluster om een middelpunt heen ligt, valt er niets te zeggen over de vorm van de clusters die het DBSCAN algoritme maakt. Een mooi voorbeeld is dat van een smiley dat uit enkel stippen bestaat. Omdat het DBSCAN algoritme enkel naar dichtheid kijkt, zal deze smiley volgens het algoritme uit 4 clusters bestaan: twee ogen, de mond en de cirkel.
Clusterkwaliteit
De drie besproken algoritmes, maar ook de velen andere algoritmes, hebben allemaal zo hun plus- en minpunten. Het hangt van de dataset af welk algoritme de beste clusters maakt. Het bepalen van de beste methode kan vooraf, maar dit is geen vereiste. Op dezelfde dataset kan namelijk met verschillende algoritmen clusters gemaakt worden. Deze clusters kunnen vervolgens naast elkaar gelegd worden om de kwaliteit van deze clusters te evalueren en de methode te identificeren die voor déze dataset het beste werkt.

Segmentatie versus Clustering: de Verdieping
Maar wat maakt een cluster goed? Een goed cluster is homogeen, de personen binnen dit cluster lijken op elkaar. Daarnaast is het ook belangrijk dat er voldoende verschillen tussen mensen uit verschillende clusters zijn. Als de personen in cluster A en B nagenoeg hetzelfde zijn, hadden deze clusters net zo goed samengevoegd kunnen worden. De twee belangrijke termen in clusterevaluatie zijn dus homogeen en heterogeen. Homogeniteit binnen, en heterogeniteit tussen de verschillende clusters.
 Silhouette Analyse maakt gebruik van deze concepten om de clusters die het algoritme gemaakt heeft te evalueren. Uit deze analyse volgt de Silhouette Coefficient, een getal tussen -1 en 1. Een hoge score duidt op clusters met een hoge dichtheid die goed van elkaar gescheiden zijn, waar een negatieve score een aanwijzing is dat er datapunten aan de verkeerde clusters zijn toegewezen. In de praktijk zijn Silhouette scores van 1 niet realistisch en is een score van 0,5 al heel behoorlijk.
Silhouette Analyse maakt gebruik van deze concepten om de clusters die het algoritme gemaakt heeft te evalueren. Uit deze analyse volgt de Silhouette Coefficient, een getal tussen -1 en 1. Een hoge score duidt op clusters met een hoge dichtheid die goed van elkaar gescheiden zijn, waar een negatieve score een aanwijzing is dat er datapunten aan de verkeerde clusters zijn toegewezen. In de praktijk zijn Silhouette scores van 1 niet realistisch en is een score van 0,5 al heel behoorlijk.
Een lage Silhouette Score hoeft overigens niet het eindstation te zijn.
Meer weten over hoe jouw bedrijf datagedreven kan worden met behulp van clustering? Neem vrijblijvend contact op.
We drinken graag een digitale kop koffie met je.